

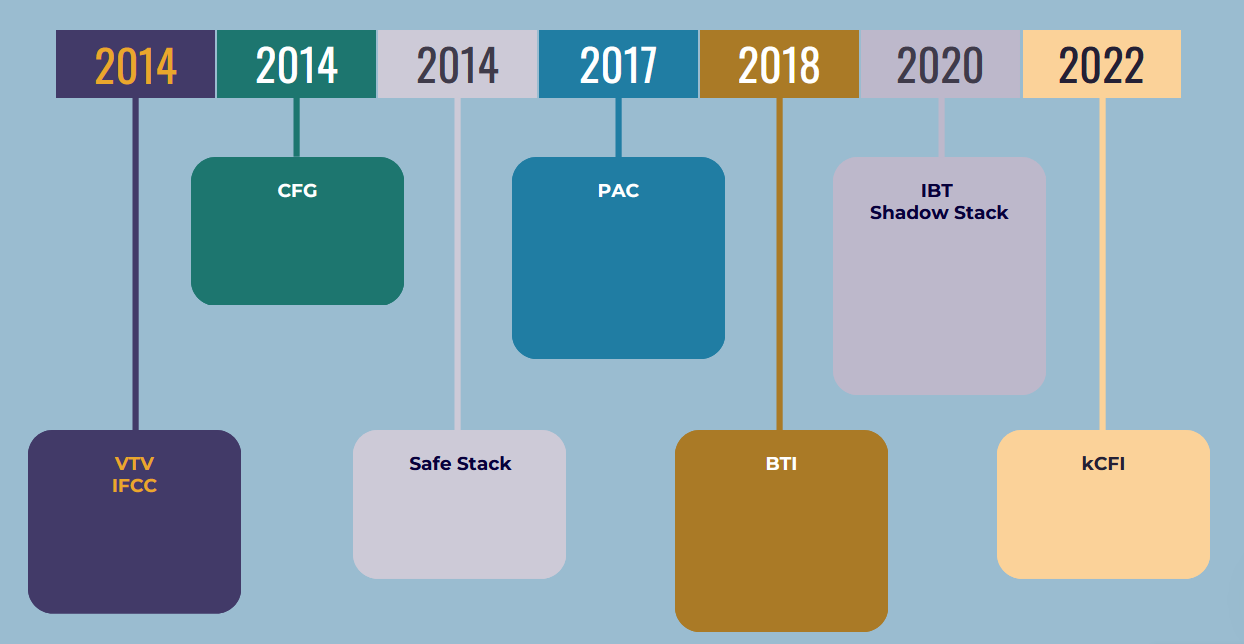
In this part we will discuss about the second generation mitigations timeline.
Second generation mitigations ( Gods)
After the introduction of ASLR, the advancement in mitigations against memory corruption has been impeded due to the implementation of sufficient mitigations across all platforms in the early 2000s. However, over time, offensive researchers have continuously presented bypasses and limitations of these initial generation mitigation techniques. Some of the primary limitations that persist include
- the presence of ROP, JOP, or any form of code reuse attacks, even with the incorporation of most of the aforementioned techniques.
- indirect function pointers remain unsecured
- heap-based memory corruption can still result in code execution.
These challenges have prompted the security industry to shift its focus towards mitigations that play a crucial role in preventing the exploitation of memory corruption, rather than solely detecting or preventing the corruption itself. This is particularly important in scenarios where the first generation techniques fail, whether due to the aforementioned issues or any other reasons.
In response to these requirements, the security industry has primarily concentrated on the concept of CFI (Control Flow Integrity). CFI serves as the fundamental principle behind all second generation techniques, which will be discussed below.
Control Flow Integrity (CFI)
Control flow integrity based mitigation techniques are the one that mitigate the exploitation of memory corruption against arbitrary code execution that can happen due to cases like function pointer modification or virtual table pointer modification. Note that they don’t protect or detect the memory corruption itself rather than prevent its exploitation. From the name you can guess that it work to maintain the control flow integrity of program execution with one goal to prevent or detect any illegal branches or redirections. From the CFI wiki:
Attackers seek to inject code into a program to make use of its privileges or to extract data from its memory space. Before executable code is commonly made read-only, an attacker could arbitrarily change the code as it is run, targeting direct transfers or even do with no transfers at all. After W^X became widespread, an attacker wants to instead redirect execution to a separate, unprotected area containing the code to be run, making use of indirect transfers: one could overwrite the virtual table for a forward-edge attack or change the call stack for a backward-edge attack (return-oriented programming). CFI is designed to protect indirect transfers from going to unintended locations.
Let’s look at the below control flow diagram to understand it better:
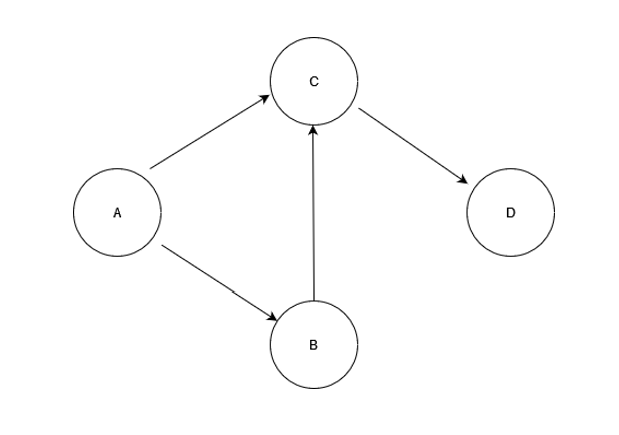
For functions from A to D, the default and legal control flow / call graph looks something like above. With CFG in place, any illegal control transfer will be blocked or detected during runtime.
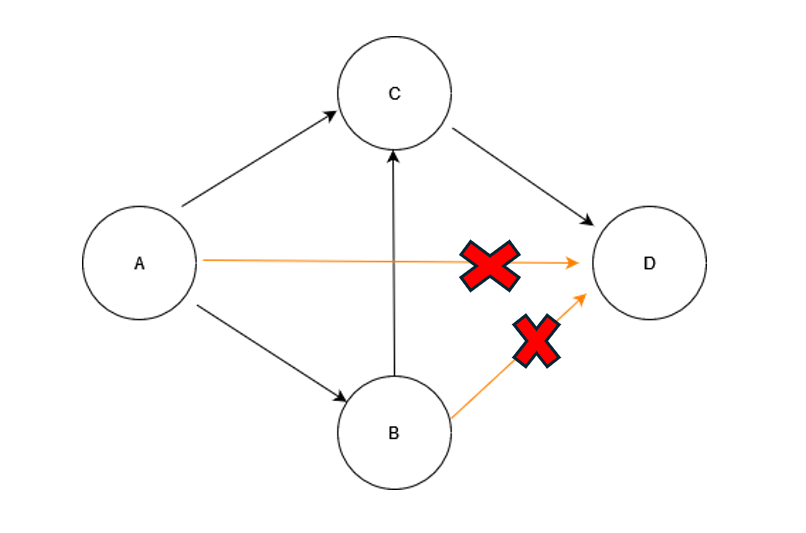
The CFI can be implemented for one of the following cases:
- Forward edge Integrity
- Backward edge integrity
Both can be explained using below code illustration:
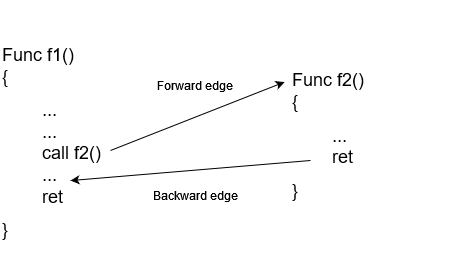
For the above high level implementation, Forward edge integrity will take care that function f1 will only call f2 or f2 is only called from f1. Whereas Backward edge integrity will take care that ret or function exit from f2 will only return to f1. For a successful CFI, both forward and backward edges would need to be protected to maintain control flow integrity and prevent attackers from diverting the program's execution in any direction.
Initial CFI implementations
In early stage CFI implementations like CCFIR and bin-CFI, Every instruction that is the target of a legitimate control-flow transfer is assigned a unique identifier (ID), and checks are inserted before control-flow instructions to ensure that only valid targets are allowed. Direct transfers have a fixed target and they do not require any enforcement checks. However, indirect transfers, like function calls and returns, and indirect jumps, take a dynamic target address as argument. As the target address could be controlled by an attacker due to a vulnerability, CFI checks to ensure that its ID matches the list of known and allowable target IDs of the instruction. The implementation can be understood better using below control flow graph:
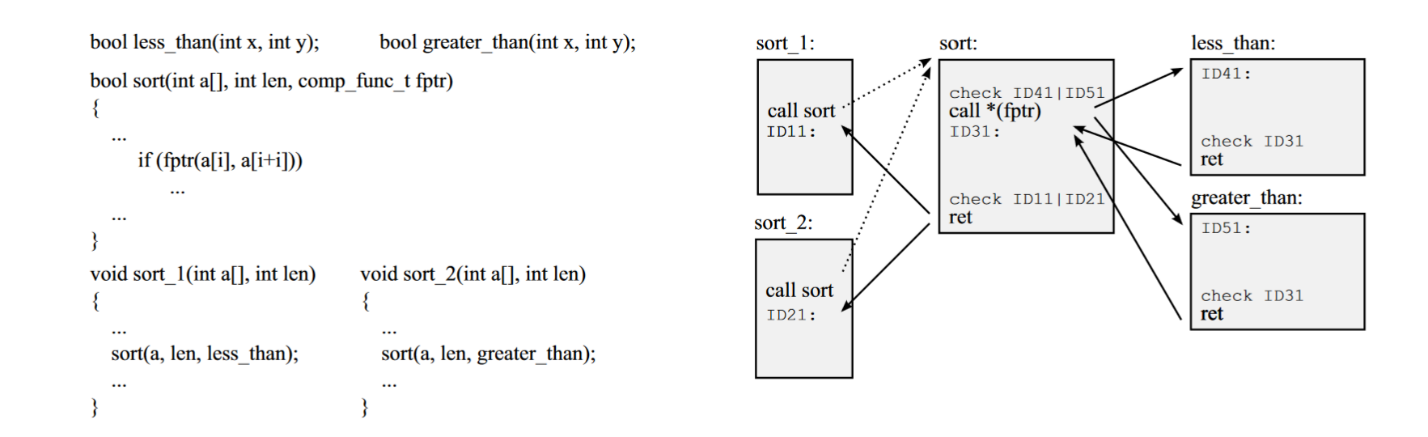
CFI introduces labels and checks for all indirect transfers. Control-flow transfers checked by CFI are shown in solid lines.
Source: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6956588
In the year 2005, the initial surface of CFI research became publicly accessible. Subsequently, numerous additional researchers emerged over the course of several years, presenting evidence of various forms of control flow integrity. However, the primary release of CFI that was readily accessible occurred in 2014 for both Windows and Linux operating systems, with both the compilers of Windows and Linux incorporating some level of support for CFI. In 2014, Linux implemented its first CFI implementation, drawing upon the research conducted by the Google team as outlined in their paper titled "Enforcing Forward-Edge Control-Flow Integrity in GCC & LLVM". Following suit, Windows also introduced CFI support in November 2014, referring to it as Control Flow Guard. Given that the Linux implementation gained public exposure first, let us delve into the CFI implementation within the Linux system.
Note: We will first go through forward edge CFI and then backward edge CFI
Forward edge CFI
Forward edge CFI in linux
In 2014, few google researchers have implemented the first practical CFI implementation. This particular implementation was employed internally in conjunction with Chromium and a select few other products, prior to its public release in August of that year. Consequently, this CFI implementation was integrated into both the GCC and LLVM compilers during the same aforementioned year. This initial work contain two different methods for CFI:
- VTV – Virtual table verification
- IFCC – Indirect function-call checks
Both methods have been implemented in order to enforce the integrity of forward edges and primarily focus on safeguarding against arbitrary code execution resulting from memory corruption in the heap. The authors have observed that, although the process stack has already been adequately protected through the implementation of multiple mitigation measures up until 2014, the heap area of the process remains susceptible to memory corruptions, which can lead to arbitrary code execution without any significant mitigations in place. This has served as a motivation for the authors to incorporate compiler-based mechanisms, with the aim of further enhancing the protection and integrity of program control data, with particular emphasis on the integrity of control-transfer data stored in the heap.
VTV - Virtual table verification
The goal of VTV is to protect virtual calls in C++. The motivation behind this mitigation is to protect common types of code hijacking that happen in C++ based memory implementation due to heap exploitations.
From the name, you can predict that VTV is use to provide integrity of vtables present in C++ code. Since most indirect calls in C++ are through vtable, this mitigation is well suited for programs written in C++. We are not going to look into details of Vtable modifications works, but let’s summarize it at high level:
The vtables themselves are placed in read-only memory, so they cannot be easily attacked. However, the objects making the calls are allocated on the heap. An attacker can make use of existing errors in the program, such as use-after-free, to overwrite the vtable pointer in the object and make it point to a vtable created by the attacker. The next time a virtual call is made through the object, it uses the attacker’s vtable and executes the attacker’s code.
To protect the above scenario, VTV verifies the validity, at each call site, of the vtable pointer being used for the virtual call, before allowing the call to execute. In particular, it verifies that the vtable pointer about to be used is correct for the call site, i.e., that it points either to the vtable for the static type of the object, or to a vtable for one of its descendant classes. The compiler passes to the verifier function the vtable pointer from the object and the set of valid vtable pointers for the call site. If the pointer from the object is in the valid set, then it gets returned and used. Otherwise, the verification function calls a failure function, which normally reports an error and aborts execution immediately.
VTV has two pieces: the main compiler part, and a runtime library (libvtv), both of which are part of GCC. In addition to inserting verification calls at each call site, the compiler collects class hierarchy and vtable information during compilation, and uses it to generate function calls into libvtv, which will (at runtime) build the complete sets of valid vtable pointers for each polymorphic class in the program.
To keep track of static types of objects and to find sets of vtable pointers, VTV creates a special set of variables called vtable-map variables (read only), one for each polymorphic class. At runtime, a vtable-map variable will point to the set of valid vtable pointers for its associated class. When VTV inserts a verification call, it passes in the appropriate vtable-map variable for the static type of the object, which points to the set to use for verification.
VTV in action
Consider the following program:
To use compile binary with VTV enable through clang use the following command:
After compiling let’s compare the code difference with and without the CFI-VTV enabled.
Before:
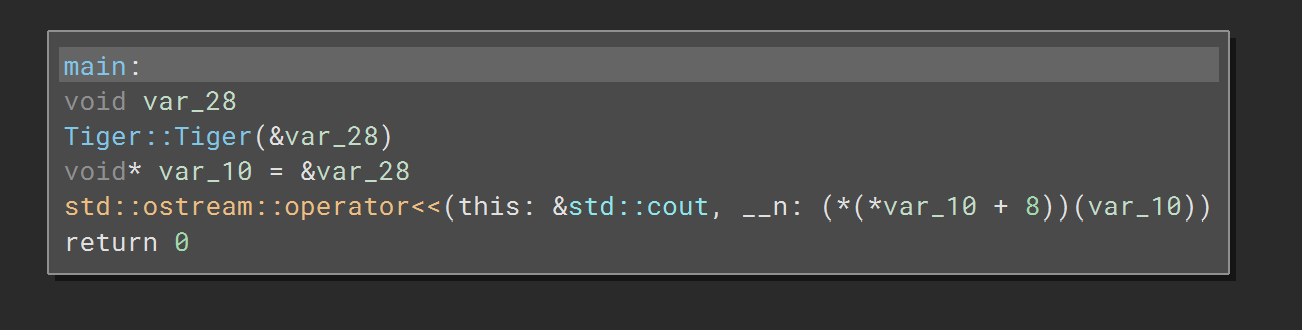
After:
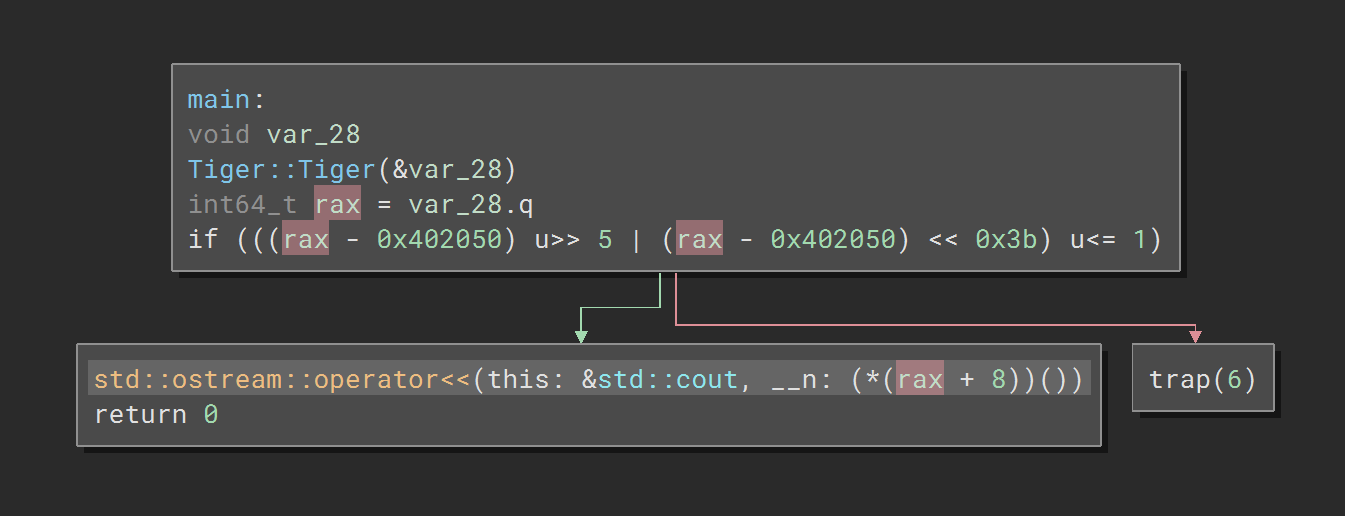
In the second image you will notice that before calling a1->getmass() (address [rax+8]), it is been verified if it is in the range of valid call site which is added during IR phase of compilation. The check can be explained in more details here: https://clang.llvm.org/docs/ControlFlowIntegrityDesign.html
IFCC: Indirect Function-Call Checks
Unlike VTV, IFCC mechanism protect integrity of all kinds of indirect calls. , it protects indirect calls by generating jump tables for indirect-call targets and adding code at indirect-call sites to transform function pointers, ensuring that they point to a jump-table entry. Any function pointer that does not point into the appropriate table is considered a CFI violation and will be forced into the right table by IFCC. The valid jump table entries are again created based on same function prototypes.
IFCC In action:
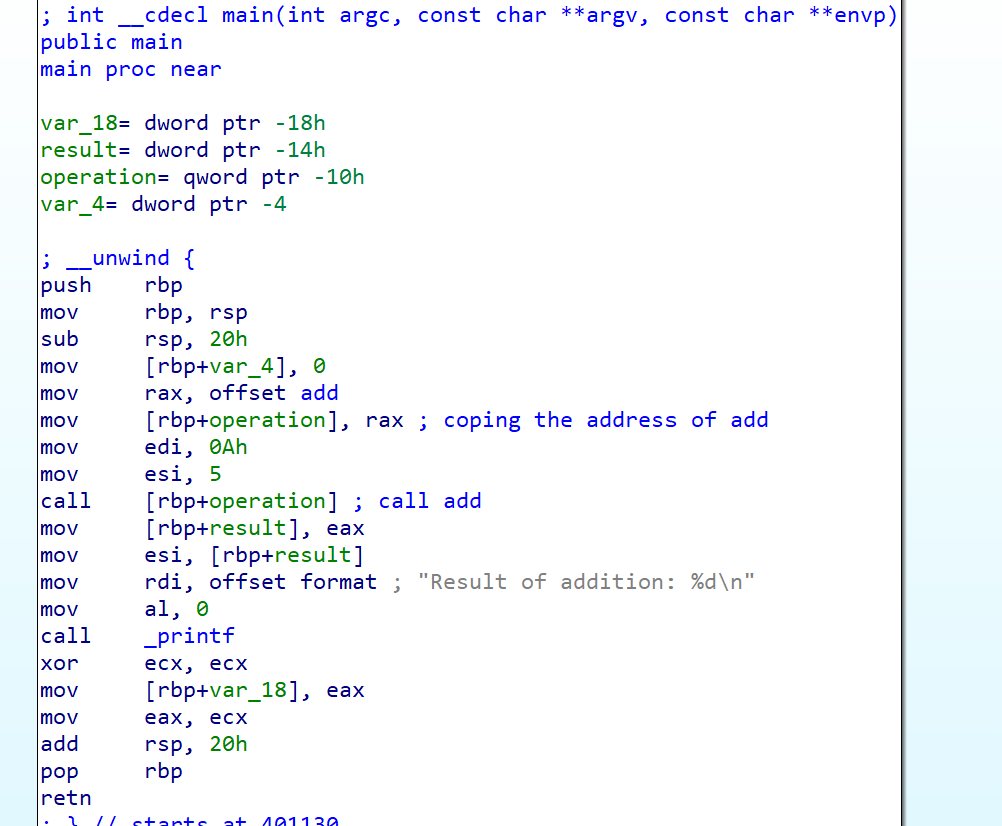
Let’s look at the following C program:
To compile the program with IFCC, use the following command:
Let’s compare the assembly sequence of both cases in IDA:
Before
After:
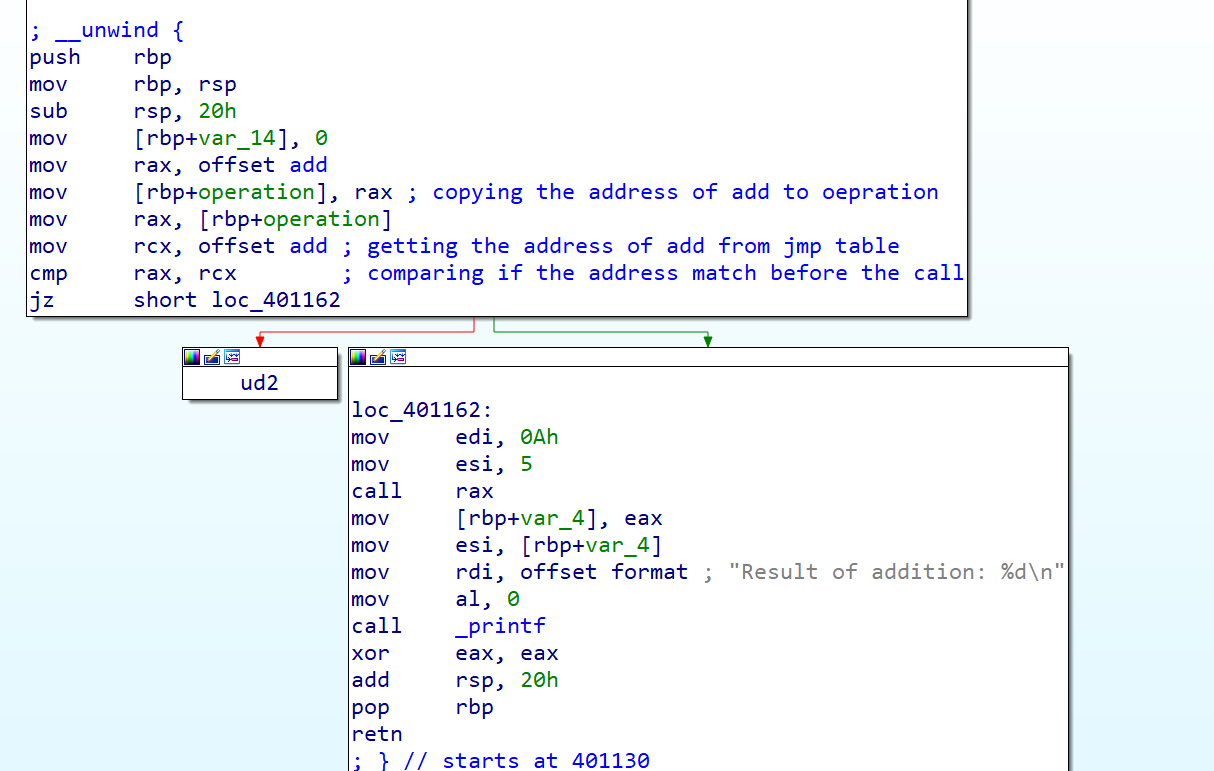
In the second case where IFCC is enabled, before calling add through operation (call rax), the address is first verified if matches the address in the jmp table ( mov rcx, offset add and cmp rax, rcx) or not. Since we only have 1 address in the jump table, the check is straight forward but in case of multiple entries, you will see ror (rotate) instruction to verify if the jump index is within range.
Other CFI support in clang:
Clang also support few other schemes that enhance the overall CFI mitigation. These schemes mostly rely on verifying function prototype before jumping to that location. Listed in detail below.
-fsanitize=cfi-cast-strict - If a class has a single non-virtual base and does not introduce or override virtual member functions or fields other than an implicitly defined virtual destructor, it will have the same layout and virtual function semantics as its base. By default, casts to such classes are checked as if they were made to the least derived such class.
-fsanitize=cfi-derived-cast and -fsanitize=cfi-unrelated-cast - These scheme checks that pointer casts are made to an object of the correct dynamic type; that is, the dynamic type of the object must be a derived class of the pointee type of the cast. The checks are currently only introduced where the class being casted to is a polymorphic class. First one is bad casts from a base class to a derived class and 2nd one is bad casts from a pointer of type void* or another unrelated type.
-fsanitize=cfi-nvcall - This scheme checks that non-virtual calls take place using an object of the correct dynamic type; that is, the dynamic type of the called object must be a derived class of the static type of the object used to make the call.
-fsanitize=cfi-mfcall - This scheme checks that indirect calls via a member function pointer take place using an object of the correct dynamic type. Specifically, we check that the dynamic type of the member function referenced by the member function pointer matches the “function pointer” part of the member function pointer, and that the member function’s class type is related to the base type of the member function.
To compile the code with all the CFI mitigation in place, you can use following flag: -fsanitize=cfi
Resources:
https://clang.llvm.org/docs/ControlFlowIntegrity.html
CFI in linux kernel
Forward edge CFI was first introduced in android linux kernel upstream in 2018 which was later added in linux kernel upstream in 2021. The first implementation has support for IFCC from CLANG in linux kernel. It can be controlled using CONFIG_CFI_CLANG and once set the compiler injects a runtime check before each indirect function call to ensure the target is a valid function with the correct static type. With CFI enabled, the compiler injects a __cfi_check() function into the kernel and each module for validating local call targets. Similar to what we seen in IFCC, during linux kernel compilation clang implements indirect call checking using jump tables and offers two methods of generating them. With canonical jump tables, the compiler renames each address-taken function to <function>.cfi and points the original symbol to a jump table entry, which passes __cfi_check() validation.
You can check the PR here: https://github.com/torvalds/linux/commit/cf68fffb66d60d96209446bfc4a15291dc5a5d41
kCFI – The fine grained CFI scheme for linux kernel
In 2022 kernel version 6.1.X, linux have merged a new patch for CFI called kCFI which is a fine grained CFI scheme that overcomes almost all the major issues and limitations of earlier CFI implementation from CLANG. kCFI’s main goal is to improve fine grained CFI scheme for indirect call redirection issues in linux kernel. It is totally dependent on instrumentation, and requires no runtime component. This decreases the overhead that is usually seen with most CFI based implementations. kCFI provides both forward edges as well as backward edge but we will only look at examples of forward edge CFI below. But the backward edge (return guard) is implemented in a similar way. kCFI over-approximates the call graph by considering valid targets for an indirect call all those functions that have a matching prototype with the pointer used in the indirect call.
Let’s go through the original LLVM-CFI issues one by one that kCFI overcome for linux kernel:
- Limitation 1: Performance bottleneck due to jump table based CFI implementation
Jump table based IFCC implementation comes with significant performance overhead when running in linux kernel. kCFI overcomes this by having tag based assertions. Tag based CFI check can be understood with following example:

Unlike LLVM CFI, kCFI adds tags using long nop instructions and verify them before the call to an indirect function. In above snippet, prologue func has an entry-point tag that is verified at call site (b) using cmpl instruction(since rax will have the address of func). this snippet dereferences 0x4(%rax) and compares the result with the expected ID (0xbcbee9; line 2). If the two IDs match, the control jumps to the callq instruction and the indirect invocation of func takes place (lines 3 and 7); else, the bogus branch address is pushed onto the stack and kcfi_vhndl (violation handler) is invoked (lines 4–6).
- Limitation 2: There exist a vast multitude of kernel functions that possess a similar prototype, such as void foo(void), which renders them eligible as CFI targets for one another.
To reduce similar valid call site jumps, kCFI introduced call graph detaching. It can be understood using below example:
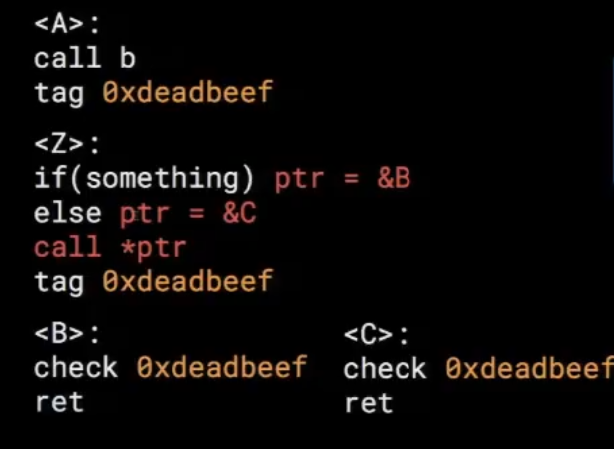
In the above code function B and C have same tag due to similar prototype, so does A due to direct call to B. In such case C is allowed to return to A even through it’s not legal. This creates a situation where transitively all instructions after a direct call to a function become valid return points to other functions with a similar prototype. This makes CFI prone to something called a bending attack.
To mitigate this problem, kCFI follows a novel approach by cloning functions instead of merging all valid return targets. In this way, a function named foo() is cloned into a new function called foo_direct(), which has the same semantics but checks for a different tag before returning. All direct calls to foo() are then replaced by calls to foo_direct(), and the tag placed after the call site is the one that corresponds to foo_direct(). This can be understood more easily with below illustration:
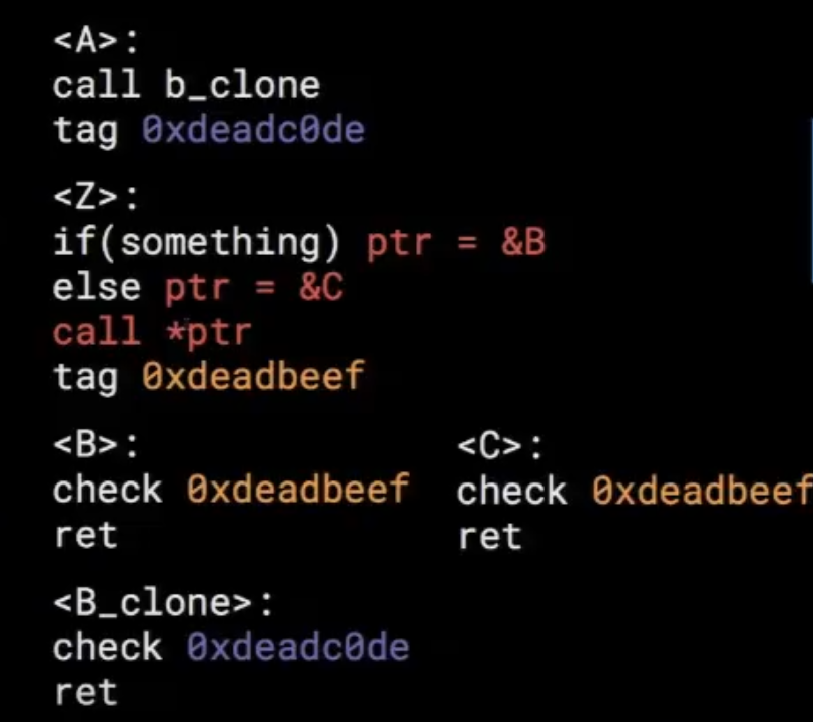
In the updated code with CGD in place, you will see A calling B_clone (having different tag) rather than B. Now, C will not be able to return to A due to tag mismatch.
- Limitation 3: Support for self-modifying code and LKMs
By employing tag-based assertions, kCFI supports self-modifying code and LKMs, as long as these portions of code are compiled in a compatible way.
- Limitation 4: Support for inline assemble code
One of the drawbacks of using LLVM-based instrumentation is that assembly sources are not touched, as this kind of code is directly translated into binaries without having an intermediate representation (IR) form. The kernel has a significant part of its code written in assembly, which includes many indirect branches. While applying CFI, if such code is left unprocessed, two major problems arise: (i) indirect branches in assembly sources are left unprotected, and (ii) tags are not placed, breaking compatibility with C functions returning to assembly, or with assembly functions being called indirectly from C code. kCFI tackles this problem through the automatic rewriting of the assembly sources assisted by information extracted during code and binary analysis.
Resources:
You can check the changelog of patch here: https://github.com/torvalds/linux/commit/865dad2022c52ac6c5c9a87c5cec78a69f633fb6
You can read about kCFI here: https://www.blackhat.com/docs/asia-17/materials/asia-17-Moreira-Drop-The-Rop-Fine-Grained-Control-Flow-Integrity-For-The-Linux-Kernel-wp.pdf
CFG (Control flow guard):
Unlike other mitigation techniques that gained popularity for their implementation in Linux, CFI gained popularity for its implementation in Windows in 2014 (in Windows 8.1). It was later removed but was reintroduced with changes in the Windows 10 Anniversary update 14393. While Windows's CFG initially received significant attention upon its release, it is limited in terms of capabilities and coverage compared to CLANG's CFI implementation. Additionally, it has faced considerable criticism due to the constant discovery of bypasses by security researchers.
Sole focus of CFG is to protect the integrity of indirect function calls in a somewhat similar way as IFCC. Let’s look at the internal details of how the CFG is implemented in windows.
CFG Internals
If the /cfguard flag is used with the msvc compiler (Visual Studio compiler), it will enable CFG when compiling the binary. The resulting binary will include a data directory called Load Configuration directory, which contains the CFG configuration details for the binary. Load Configuration directory have a structure which have few fields that are important for CFG implementation:
GuardFlags have the flags related to CFG which define what CFG mitigations are set in binary. The structure looks like below:
Functions that are valid indirect call targets are listed in the GuardCFFunctionTable, sometimes termed the GFIDS table. This is a sorted list of relative virtual addresses (RVA) that contain information about valid CFG call targets. There are two other function pointer with following usecase:
GuardCFCheckFunctionPointer provides the address of an OS-loader provided symbol that can be called with a function pointer in the first integer argument register (ECX on x86) which will return on success or will abort the process if the call target is not a valid CFG target.
The GuardCFDispatchFunctionPointer provides the address of an OS-loader provided symbol that takes a call target in register RAX and performs a combined CFG check and tail branch optimized call to the call target (registers R10/R11 are reserved for use by the GuardCFDispatchFunctionPointer and integer argument registers are reserved for use by the ultimate call target).
In addition to possessing a specific header for CFG, Windows executes two additional tasks in order to enable CFG for a binary:
- Instrument around all indirect call with _guard_check_icall check.
- Mapping CFG bitmap in process memory space during Process initialization
__guard_dispatch_icall_fptr check
CFG when enabled, msvc compiler will wrap all the indirect calls in a given binary by a call to __guard_dispatch_icall_fptr (Guard CF address dispatch-function pointer) which ensure the target address is valid. The wrapper function _guard_dispatch_icall_fptr is actually a placeholder at compile-time and will be patched by the NT loader on module loading to point to LdrpValidateUserCallTarget to do the actual check. We will look into the call in the next section for better understanding.
CFG Bitmap
The NT loader will, on a module load (see ntdll!LdrSystemDllInitBlock ), parse the Load Configuration entry to look for CFG aware capabilities and, if enabled, will generate a CFG bitmap storing all the valid targets address from the CFG whitelist in the module. __guard_dispatch_icall_fptr calls ntdll!LdrpValidateUserCallTarget which during execution verifies the call to be valid using CFG Bitmap loaded in memory.
CFGBitmap represents the starting location of all the functions in the process space. The status of every 8 bytes in the process space corresponds to a bit in CFGBitmap. If there is a function starting address in each group of 8 bytes, the corresponding bit in CFGBitmap is set to 1; otherwise it is set to 0.
Let’s take the function target address to be 0x00b01030. The address is used to get the bit in Bitmap and verified if is 1 or 0.

The highest 3 bytes (the 24 bits encircled in blue) is the offset for CFGBitmap (unit is 4 bytes/32 bits). In this example, the highest three bytes are equal to 0xb010.Therefore, the pointer to a four byte unit in CFGBitmap is the base address ofCFGBitmap plus 0xb010.
Meanwhile, the fourth bit to the eighth bit (the five bits encircled in red) have the value X. If the target address is aligned with 0x10 (target address & 0xf == 0), then X is the bit offset value within the unit. If the target address is not aligned with 0x10(target address & 0xf != 0), the X | 0x1 is the bit offset value. If the bit is equal to 1, it means the indirect call target is valid because it is a function’s starting address. If the bit is 0, it means the indirect call target is invalid because it is not a function’s starting address.
CFG in Action
Let’s compile the following program with CFG enable to check the modifications in binary due to CFG.
You can turn on CFG using following visual studio configuration options
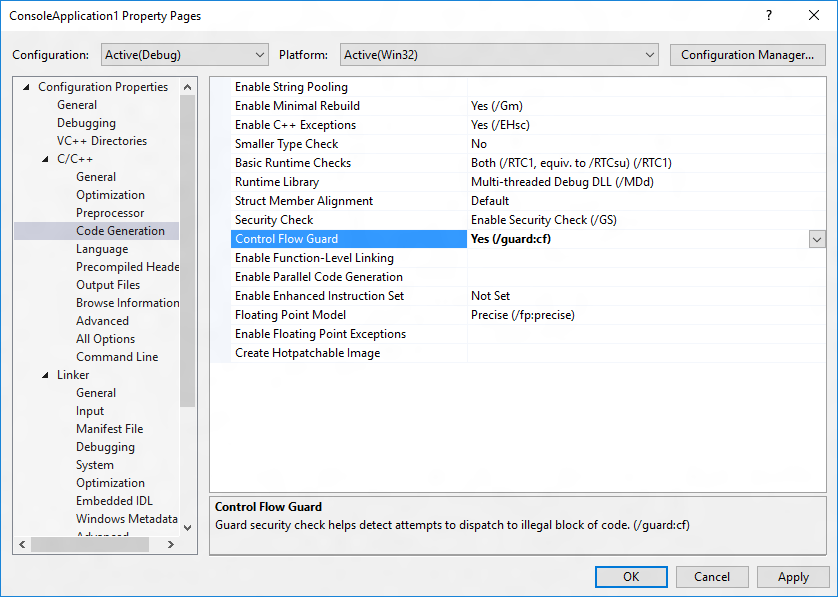
Once the binary is compiled, you can load it in PEBear to verify it has a Load Configuration data directory.
Now, let’s load the binary in IDA and look at the changes.
Before
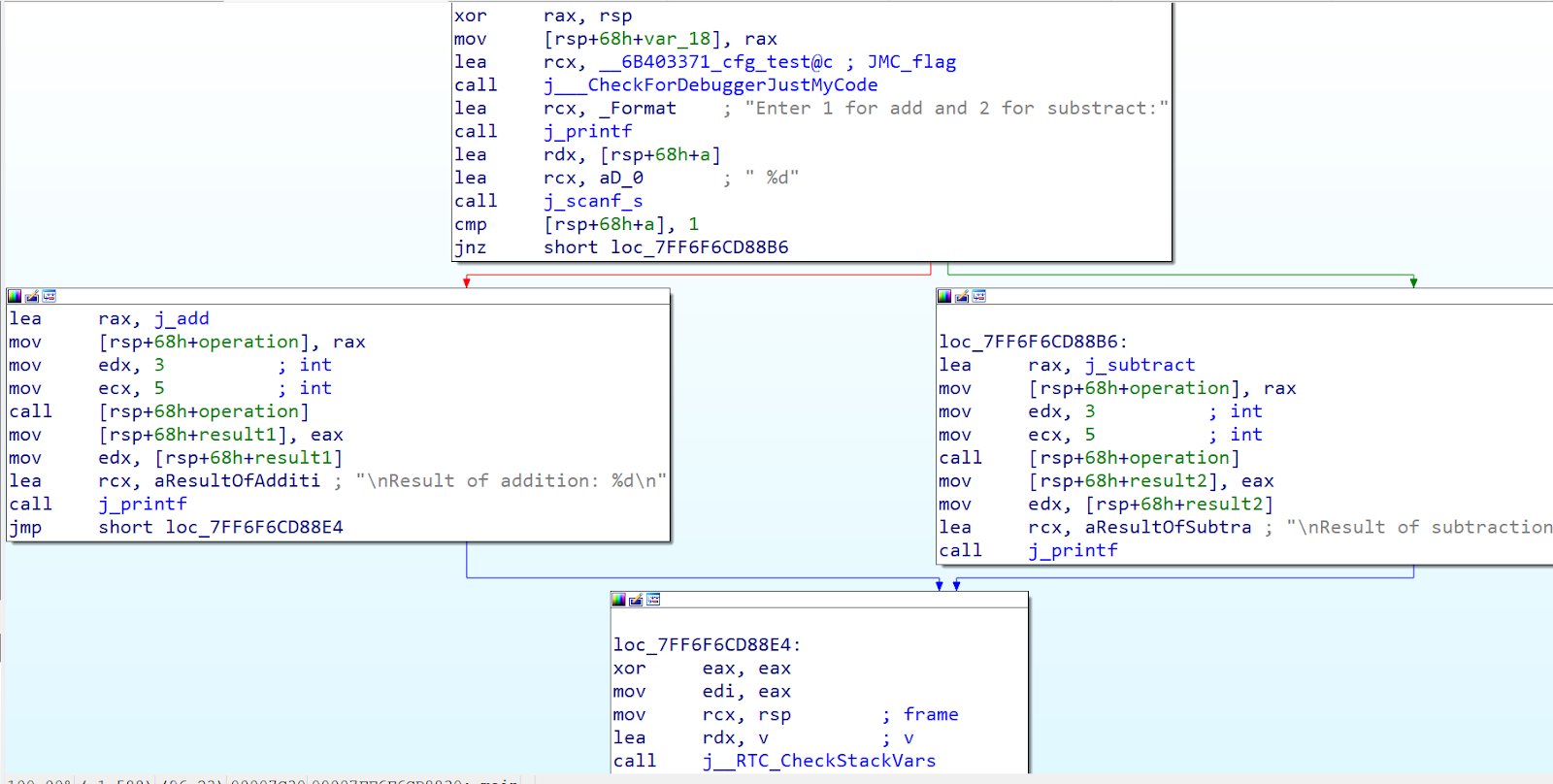
After:
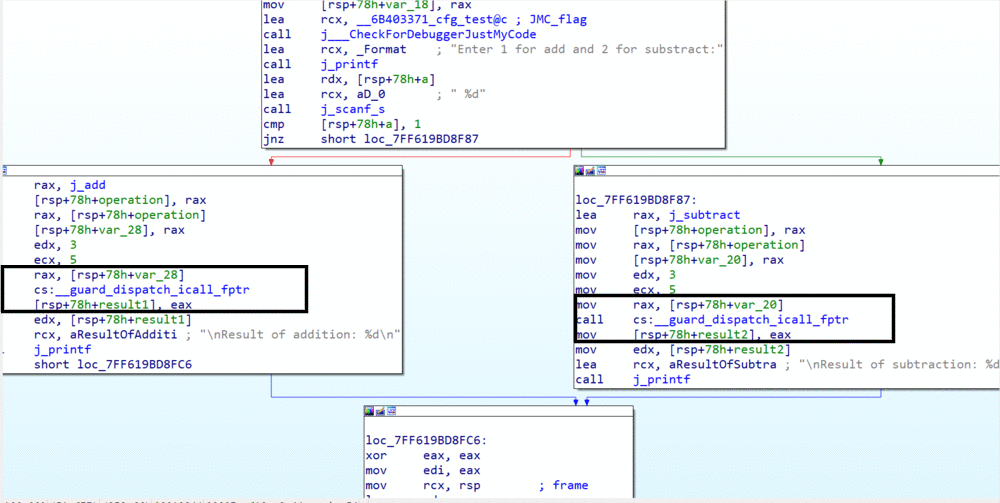
You can notice that the indirect call ( call rsp+68h+operation) gets replaced with call to _guard_dispatch_icall_fptr. The calling address is passed using rax register and variables are passed using the default calling convention rcx, rdx…
The code for verifying the call target using bitmap is present in ntdll:
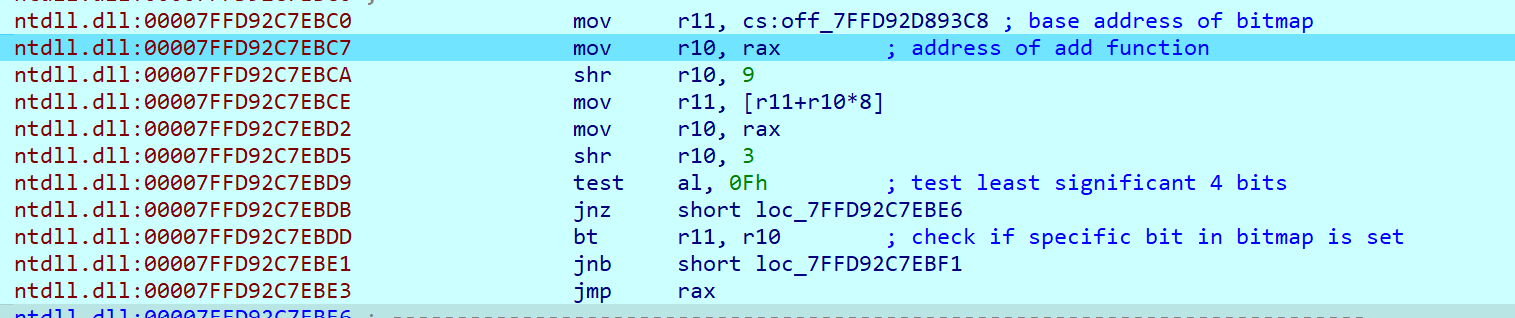
If the check fails, the execution get stopped.
Resources
http://sjc1-te-ftp.trendmicro.com/assets/wp/exploring-control-flow-guard-in-windows10.pdf
https://lucasg.github.io/2017/02/05/Control-Flow-Guard/
https://learn.microsoft.com/en-us/windows/win32/secbp/pe-metadata
XFG (extended flow guard) (Honorable mention)
Due to coarse gain nature of CFG where attacker can still call the gadgets part of valid call sites, Windows developer’s decided to come up with a fine grained solution on top of CFG
XFG adds a check on top of default CFG which verifies if the caller who called the call site is correct or not. To perform this, the compiler will generate a 55-bit hash based on the function name, number of arguments, the type of arguments, and the return type. This hash will be embedded in the code just prior to the call into XFG. Later inside LdrpDispatchUserCallTargetXFG the value is matched to be the same or not.
At the caller you will see something like below:
mov at main+2f moves the generated hash to r10. Inside _guard_xfg_dispatch_icall_fptr you will see the following:
The hash value (present in r10) is compared against the original generated value [rax-8] at the end of the function before calling the actual target.
Hardware enforced CFI mitigations
CFI mitigation gained rapid popularity following its initial integration into major platforms. However, both mitigations are disabled by default in all compilers due to the increased performance overhead. At this juncture, hardware vendors have taken it upon themselves to ensure that CFI is readily accessible. Intel and ARM both has introduced similar kind of mitigation for forward edge integrity, explained below.
BTI (branch target identification)
In the year 2018, ARM unveiled the initial hardware-enforced forward edge CFI within the ARM 8.5-A processor lineage, which was named BTI (Branch target identification). The primary objective of BTI is to forestall indirect calls from redirecting to unintended destinations, thus hindering the execution of gadgets.
BTI technical details
BTI is straightforward in terms of its implementation. If BTI is enabled, the first instruction encountered after an indirect jump must be a special BTI instruction. When BTI is turn off, this first instruction will be treated as no-op. When BTI is on, the processor check if the BTI instruction is present as the first instruction or not. Jumps to locations that do not feature a BTI instruction, instead, will lead to the quick death of the process involved.
During branching, the type of branch is stored in the PSTATE BTYPE bits. Upon reaching the destination address, the processor checks whether the first instruction is BTI or not and verifies if the value passed as operand of BTI instruction matches with PSTATE BTYPE or not.
BTI in action
Let’s compile following program to test BTI compiled code.
Compile the program with the following parameters in ARM gcc.
check the compiled code
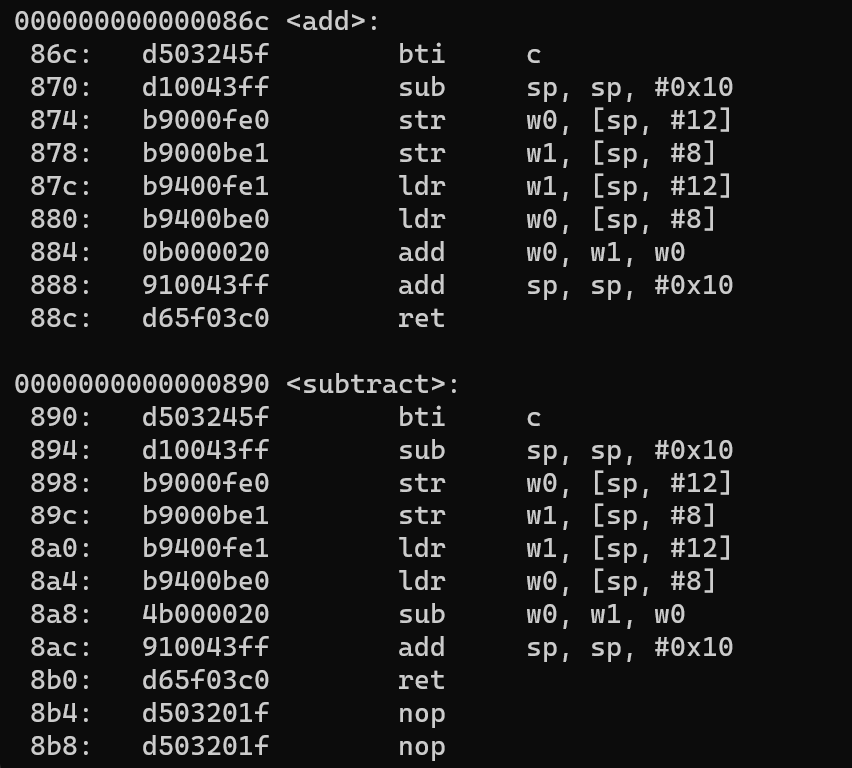
You will notice the first instruction to be replaced as BTI in above assembly snippet. The syntax for BTI is
BTI <branch type>
There are 3 variants of the BTI instruction, which are valid targets for different kinds or branches: -
- c -Branch Target Identification for function calls
- j - Branch Target Identification for jumps
- jc - Branch Target Identification for function calls or jumps.
In our case the value is BTI c since add and sub are called as indirect function calls.
IBT (Indirect Branch Tracking)
In the year 2020, Intel unveiled the particulars of the introduction of a hardware security measure called CET for Intel TigerLake processors, which became accessible to the publically in 2021. Intel CET encompasses two hardware-enforced measures referred to as Shadow stack and IBT (Indirect branch tracking). IBT represents one of the methods employed to mitigate the issue of forward edge CFI.
Similar to BTI, if IBT is enabled, the CPU will ensure that every indirect branch lands on a special instruction ( endbr32 or endbr64), which executes as a no-op. If processor finds any other instruction than the expected endbr, it will raise a control-protection (#CP) exception. The state of IBT can be understood using following state machine:
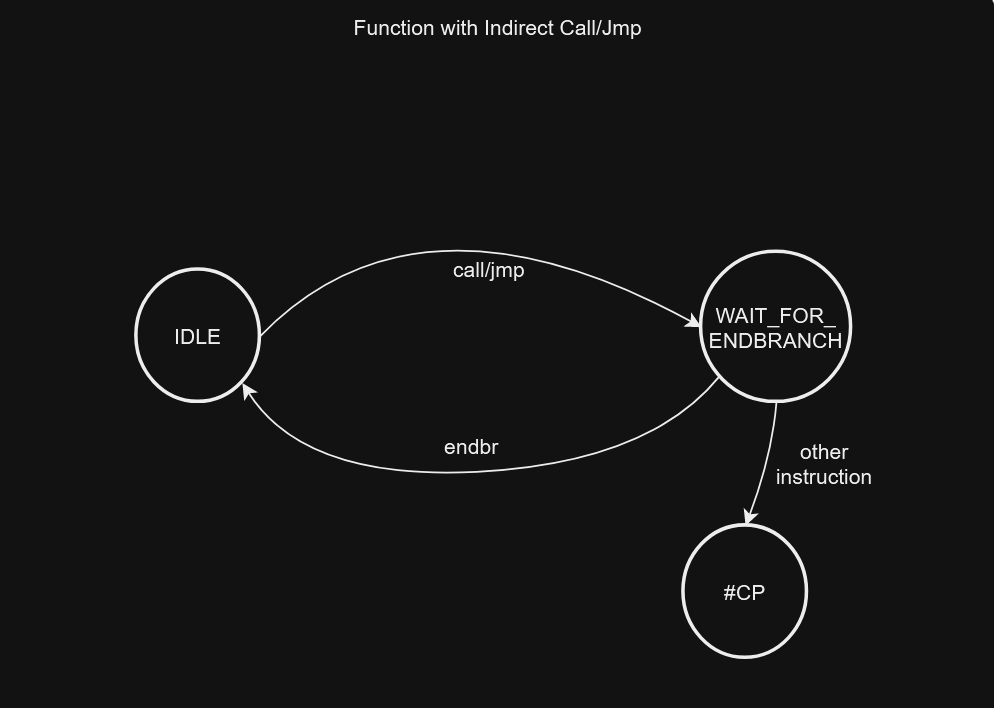
The processor implements a state machine that tracks indirect JMP and CALL instructions. When one of these instructions is seen, the state machine moves from IDLE to WAIT_FOR_ENDBRANCH state. In WAIT_FOR_ENDBRANCH state the next instruction in the program stream must be an ENDBRANCH. If an ENDBRANCH is not seen the processor causes a control protection fault (#CP), otherwise the state machine moves back to IDLE state.
IBT in action
Let’s compile the same program we used for BTI for IBT:
You will notice following calls:
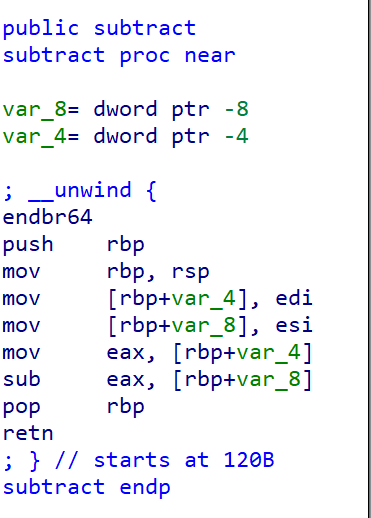
Here, the first instruction is endbr64 in all indirect calls.
In windows, you can compile binary with IBT by using the following flag in visual studio /CETCOMPAT.
FineIBT (Honorable mention)
The default IBT implementation came with the drawback of allowing Code reuse of functions that are part of the Indirect branch target to be used as gadgets. To overcome this IBT limitation, In 2021 Intel's Joao Moreira raised patches for linux kernel which was later merged in linux kernel in 2022 https://github.com/torvalds/linux/commit/931ab63664f02b17d2213ef36b83e1e50190a0aa.
Under IBT, an attacker who is able to tamper with forward-edge transfers can still “bend” the control flow towards any of the valid/allowed function-entry points marked with endbr, because the CPU cannot differentiate among different types of endbr-marked code locations. To make a robust CFI solution using hardware assisted IBT, FineIBT instruments both the callers and the callees involved in indirect forward-edge transfers and verify if the correct callee is called from a given caller. The instrumentation can be understood using the following assembly snippet.
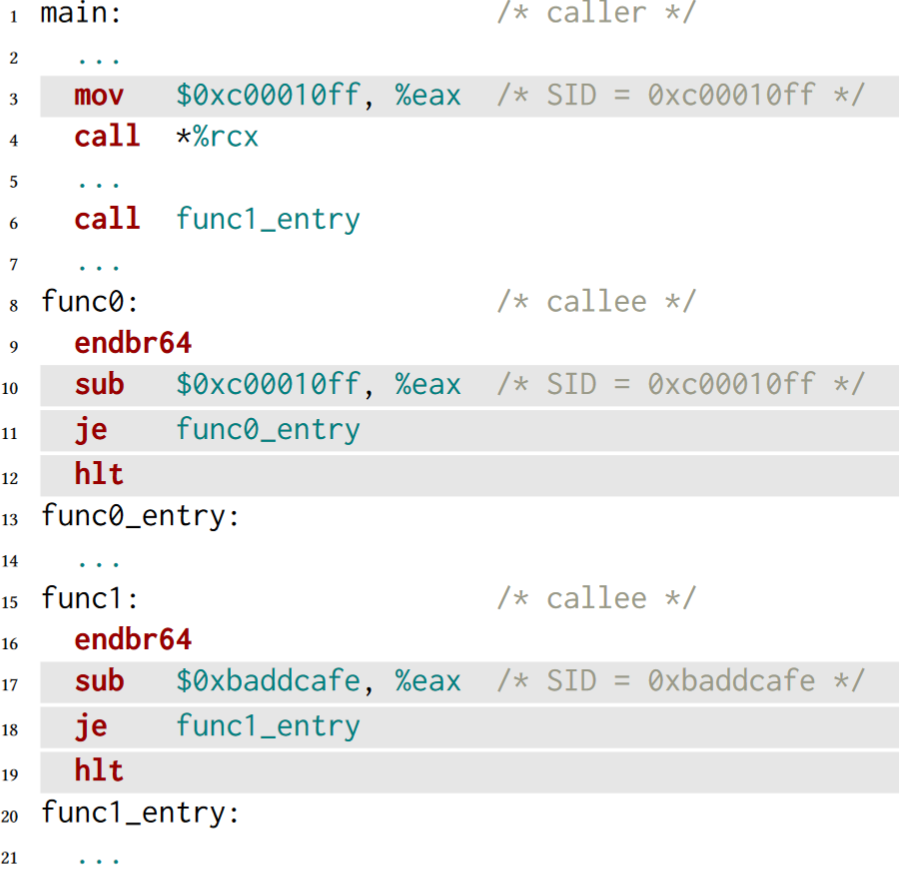
With FineIBT in place, before each indirect calls compiler instrument a code to move a random SID to any general purpose register (eax in above case) and on callee (func0), we verify if the value in %eax is matched or not using sub instruction at line 10. For all direct calls to any indirect function target, we create a clone of the original function (func1_entry) and call that rather than the original function.
Currently the technique is only supported in linux kernel.
Limitation of CFI – Forward edge
Over the years, numerous researchers surfaced that bypasses CFI completely or at a certain level. We will go through some well known cases below.
LLVM CFI limitations
Performance penalty:
Due to the inclusion of additional verification instructions and the incorporation of a runtime library, the performance of VTV can be affected, with a range of impact varying from 2% to 20% depending on how the application has been implemented i.e more virtual functions brings more performance impact.
The performance of IFCC is contingent upon the number of indirect calls executed by a program. In the majority of programs, the penalty incurred is less than 4%.
Limitation in capability:
The CFI present in CLANG is still not capable of protecting control flow divergence using CRA(Code reuse attack) based on backward edges i.e Return oriented programming.
Note: Initial stage CFI implementation bypass research which is based on finding gadget on allowed targets using ROP: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6956588
Code reuse attack for forward edge
Even though CFI’s main goal is to protect Code reuse attack like ROP, there are certain type of CRA introduced over years to defeat existing CFI implementation. One such research mentioned below:
COOP - Counterfeit Object-Oriented Programming is a code reuse attack approach targeting applications developed in C++ or possibly other object-oriented languages. At high level, it relies on finding protected targets in the application binary which can legitimately be called and doesn’t cause CFI violation.
COOP, virtual functions existing in an application are repeatedly invoked on counterfeit C++ objects carefully arranged by the attacker. Counterfeit objects are not created by the target application, but are injected in bulk by the attacker.
To understand in more details, COOP relies on existing virtual function reuse called “vfgadgets”. Vfgadgets flow can be understood using below image:
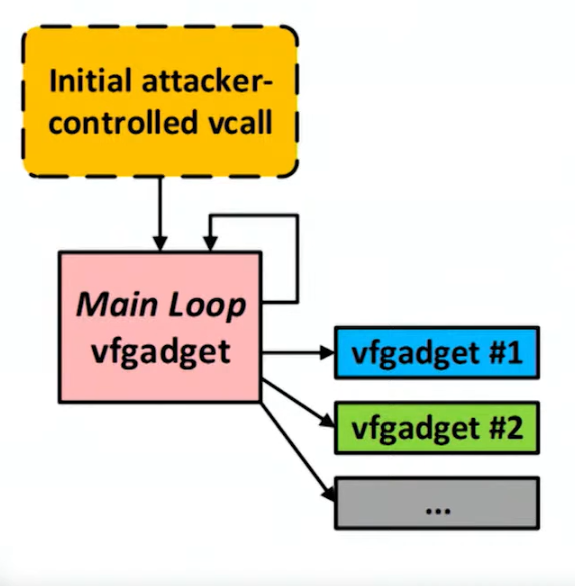
Once an attacker is able to control the vptr, it will redirect the execution to Main loop vfgadget which executes in loop. From this main loop gadget, the attacker invoke the actual vfgadget that are injected on process memory as payload.
COOP can be use to bypass most CFI implementation besides LLVM or GCC VTV and SafeDispatch.
Image source: https://www.youtube.com/watch?v=NDt7Tholxp4
You can read more about the attack here: https://ieeexplore.ieee.org/document/7163058
Limitation in linux kernel:
For linux kernel the earlier default CFI implementation that was similar to CFI-CLANG was less powerful since even though the CFI reduce the attack surface to limited call sites, in linux kernel most function have prototype of void foo(void)
Limitation of CFG
Windows implementation of CFI named Control flow guard has two implementation limitations about requirement of ASLR and alignment of guard functions. If a binary doesn’t support ASLR then CFG cannot be implemented in the following binary due to the fact that CFG relies on ASLR to work properly.
Besides that, CFG requires all guard functions to be aligned to 0x10. If the function call is not aligned to 0x10, it will use an odd bit only. This allows untrusted function call near trusted function call. In detail: CFG is able to precisely mark a valid target only if it is the only target in its address range and it is 16-byte aligned. In that case, the state will be 10. However,if a target is not aligned, or there are multiple targets in the same range, then the state will have to be set to 11, which allows branches to any address in the range. In other words,we can freely alter the lower 4 bits of a valid unaligned target and the result will still be a valid target. This enables us to reach code located near an unaligned function’s entry point, which leads to interesting code sequences. You can read more about it here: https://www.ndss-symposium.org/wp-content/uploads/2018/02/ndss2018_05A-3_Biondo_paper.pdf
Unsupported module presence in process
CFG depends on compile and link level processing. As a result, third party modules and even old versions of MS binaries are not safeguarded by CFG. Furthermore, if the main executable image is not designed for CFG, CFG will be entirely disabled during the process, even if it loads system modules that do support CFG.
JIT code bypass
CFG doesn’t support JIT generated code. It can contain unprotected code and all corresponding bits in the CFG Bitmap are set.
More details here: https://www.blackhat.com/docs/us-15/materials/us-15-Zhang-Bypass-Control-Flow-Guard-Comprehensively-wp.pdf
CFI (Backward edge Integrity)
To ensure the effectiveness of CFI in various situations, hardware manufacturers have implemented several CFI backward edge techniques that closely resemble the workings of many first-generation techniques but rely heavily on hardware. However, the initial significant advancement in backward edge was introduced as a software solution in clang in 2014, which we will examine first.
SafeStack
The initial implementation of protection for backward edges was presented in a research paper published in 2014, which focused on Code Pointer Integrity (CPI). The paper also discussed SafeStack, a key element of Code Pointer Separation that provides defense for both return addresses and local variables. This protective measure was first introduced in clang 3.8 in the same year and continues to be utilized to this day.
Introduction to CPI
CPI fully protects the program against all control-flow hijack attacks that exploit program memory bugs. In a nutshell, it protect all types of code pointer (backward or forward edge) i.e it guarantees the integrity of all code pointers in a program (e.g., function pointers, saved return addresses) and thereby prevents all control-flow hijack attacks, including return-oriented programming.
The key idea behind CPI is to split process memory into a safe region and a regular region. CPI uses static analysis to identify the set of memory objects that must be protected in order to guarantee memory safety for code pointers. This set includes all memory objects that contain code pointers and all data pointers used to access code pointers indirectly. All objects in the set are then stored in the safe region, and the region is isolated from the rest of the address space (e.g., via hard-ware protection). The safe region can only be accessed via memory operations that are proven at compile time to be safe or that are safety-checked at runtime.
Safe Stack technical details
Safe stack is to protect the return address. It does that by placing all proven-safe objects(return address and local variables) onto a safe stack located in the safe region. The safe stack can be accessed without any checks.
The safe stack mechanism consists of a static analysis pass, an instrumentation pass, and runtime support. The analysis pass identifies, for every function, which objects in its stack frame are guaranteed to be accessed safely and can thus be placed on the safe stack; return addresses and spilled registers always satisfy this criterion. For the objects that do not satisfy this criterion, the instrumentation pass inserts code that allocates a stack frame for these objects on the regular stack.
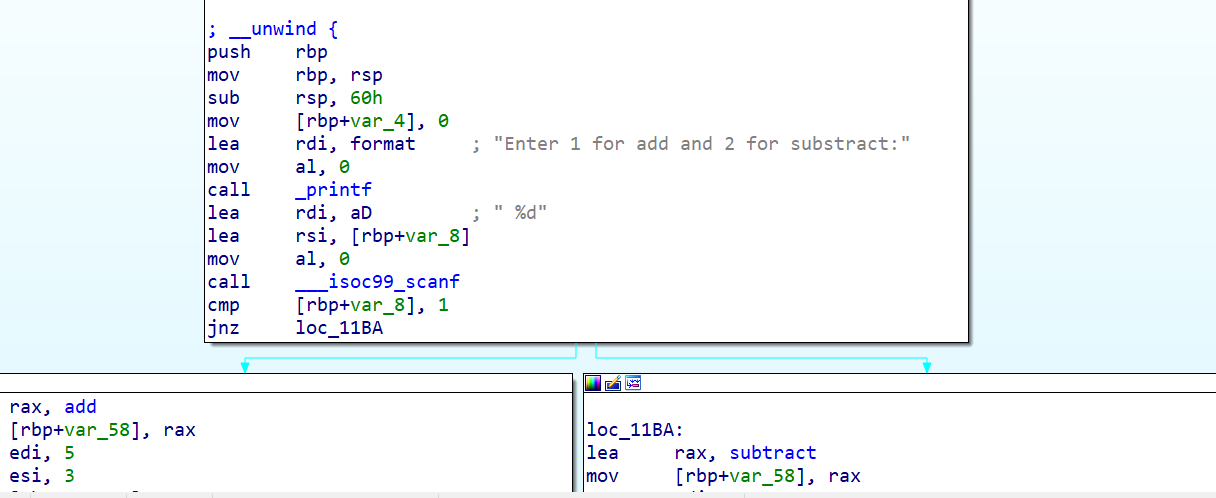
Safe Stack in action
Let’s compile our above mentioned standard program with safe stack protection on. You can compile file with clang and pass -fsanitize=safe-stack flag.
You will see some instrumentation added to the program function.
Before:
After:
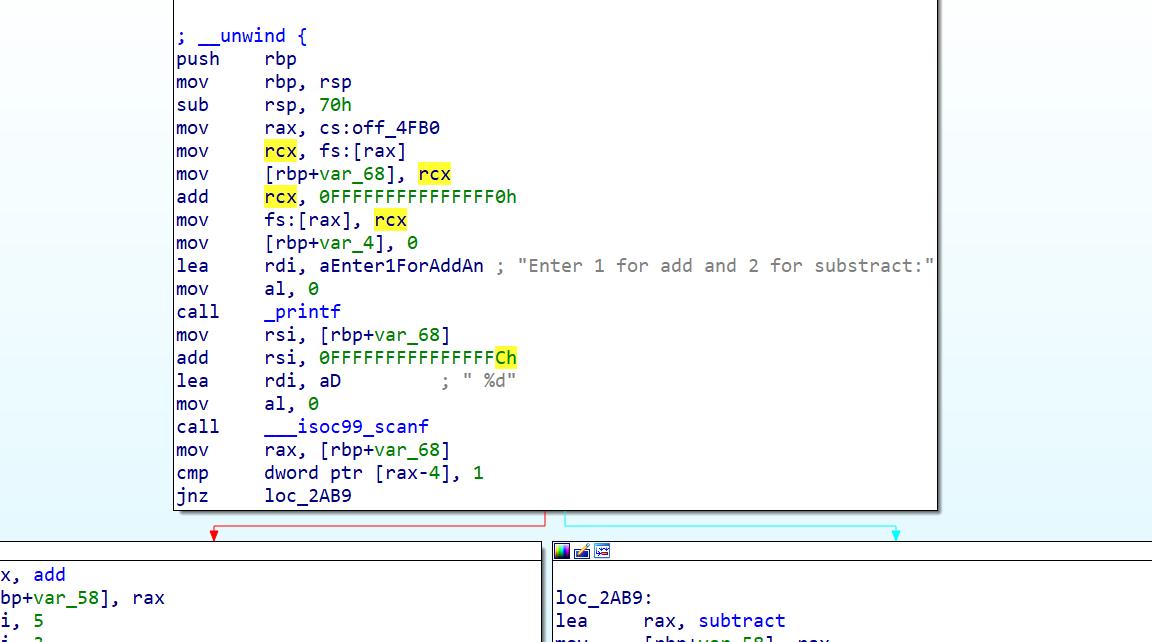
Resources:
You can read more about SafeStack and CPI here: https://dslab.epfl.ch/pubs/cpi.pdf.
TODO: Add safestack bypasses section
PAC (Pointer authentication code)
ARM has the distinction of introducing Pointer authentication, the first technique for backward edge, which was introduced in ARM v8.3 architecture that was released in late 2016. Subsequently, support for PA was added in gcc in 2017 (v7) and in the Linux kernel in 2018.
Pointer authentication not only focuses on protecting backward edges, but is also effective in scenarios involving modifications of all types of pointers, such as function or data pointer validations. However, it is most commonly used by compilers to protect backward edges, specifically return addresses.
Pointer authentication technical details
From the title, you can anticipate the purpose of pointer authentication, which is to verify whether a pointer is valid or not before utilizing it. ARM incorporates a PAC (Pointer Authentication Code) into every pointer that needs protection prior to storing it in memory, and confirms its integrity before using it. This PAC is stored in the top byte ignore bits (usually the 48th to 64th bit if Tagging is deactivated) of the virtual address space in ARM. In order to alter a protected pointer, an attacker would need to discover or guess the correct PAC in order to gain control over the program's flow.
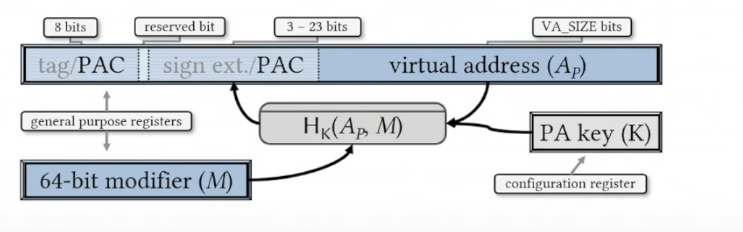
ARM uses a key generated for specific context to create PAC. The pointer authentication specification defines five keys: two for instruction pointers, two for data pointers and one for a separate general-purpose instruction for computing a MAC over longer sequences of data. The instruction encoding determines which key to use. For protection of key, it is stored in internal registers and are not accessible by EL0 (user mode), but otherwise are not tied to exception levels. Whenever a process is created, the kernel(running in EL1) will generate a random key and store it in that process's context; the process will then be able to use that key to sign and authenticate pointers, but it cannot read the key itself.
Generation and use of PAC is handled by two set of instructions: PAC* and AUT*. PAC* is used to compute and add PAC and AUT* is used for verifying the PAC. To generate PAC three values are used, the pointer itself, a secret key hidden in the process context, and a third value like the current stack pointer passed through a cipher called QARMA. PAC is the truncate output of the resulting cryptographic operation.
Implementation of PAC
PAC can be enabled in AARCH64 architecture using CONTROL.PAC_EN or CONTROL.UPAC_EN flags. The Pointer authentication flow can be understood using the diagram below.
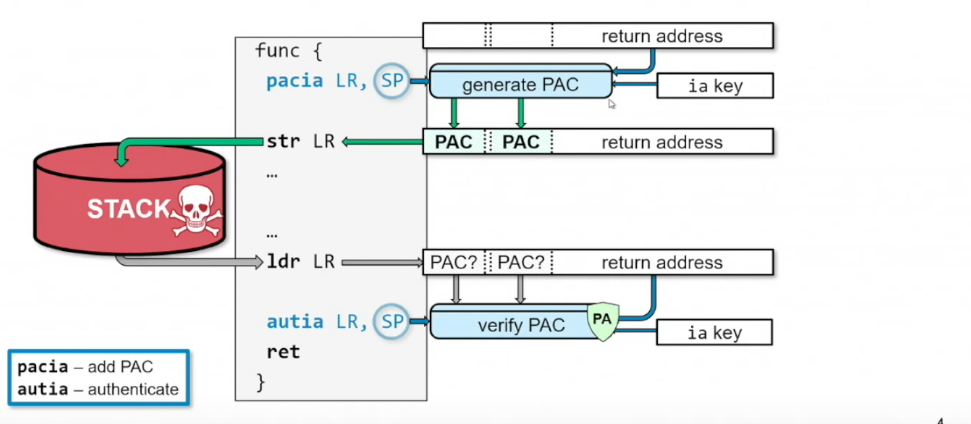
Source: USENIX Security '19 - PAC it up: Towards Pointer Integrity using ARM Pointer Authentication
Pointer authentication in action:
Let’s compile our above program with Pointer authentication on. You can pass one of the following flag to gcc:
or
Let’s check the changes of main() function due to PAC after compilation:
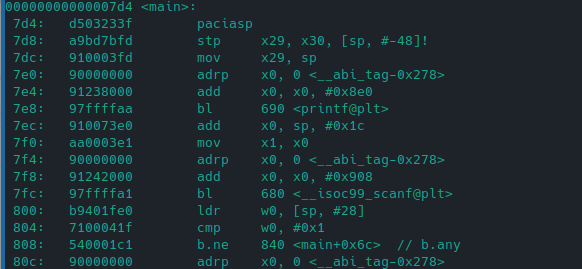
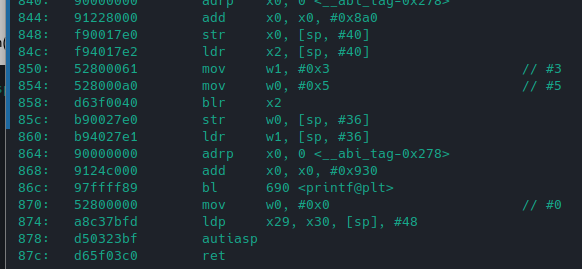
You will see paciasp instruction at top which will generate PAC and store it in stack and rsp register. At the epilog of the program, autiasp will verify if the value of PAC in stack is similar to what is present in address top bytes or not. On difference, the program will crash.
Note: You will not see pointer authentication been used in add or subtract function since these function don’t have local variables.
Resources
https://www.qualcomm.com/content/dam/qcomm-martech/dm-assets/documents/pointer-auth-v7.pdf
Shadow stack
As part of CET, intel has introduced shadow stack (along with IBT) from Intel Tigerlake processor released in 2020. Shadow stack is used to protect backward edge (i.e return address modification).
A shadow stack is a secondary stack allocated from memory which cannot be directly modified by the process. When shadow stacks are enabled, control transfer instructions/flows such as near call, far call, call to interrupt/exception handlers, etc. store their return addresses to the shadow stack and the process stack.
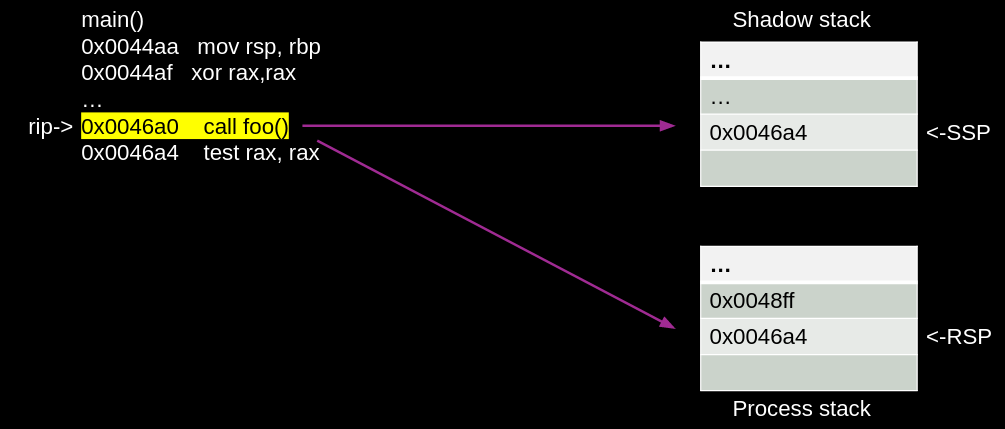
The ret instruction pops the return address from both stacks and compares them. In the event that the return addresses from the two stacks do not match, the processor will indicate a control protection exception (#CP).
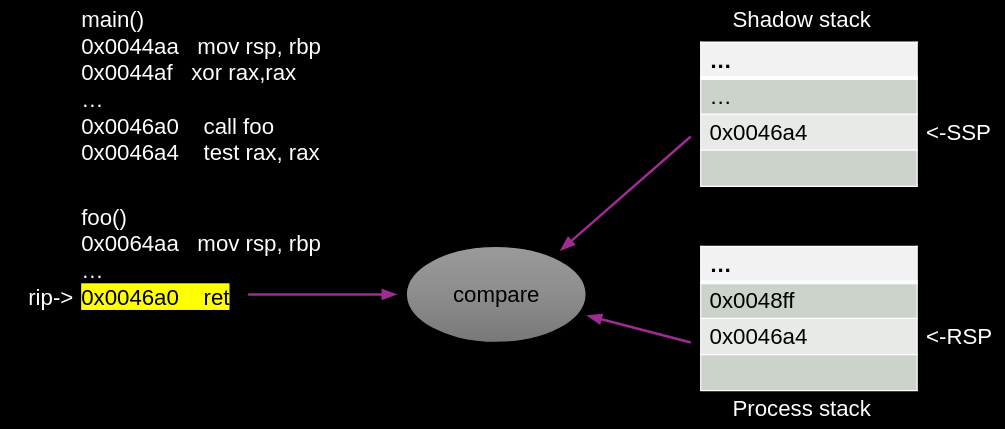
The shadow stack is protected from tamper through the page table protections such that regular store instructions cannot modify the contents of the shadow stack. To provide this protection the page table protections are extended to support an additional attribute for pages to mark them as “Shadow Stack” pages.
Note: The idea of shadow stack originated from 2005 CFI research paper: https://dl.acm.org/doi/10.1145/1102120.1102165
Shadow stack in Linux - To compile binary with shadow stack support you can use -fcf-protection flag in both gcc and llvm. You will not see any instruction modification in CET compiled binary for shadow stack since it’s working is invisible from application.
Shadow stack in windows - In windows, you can use /CETCOMPAT flag in visual studio 2019+ to compile binary with shadow stack support. You can read about shadow stack windows implementation from windows-internals blog https://windows-internals.com/cet-on-windows/.
Note: Before introduction of Intel CET, Windows implemented software based shadow stack technology called Return flow guard in Windows 10 Redstone 2 14942. You can read about RFG here: https://xlab.tencent.com/en/2016/11/02/return-flow-guard/
TODO: Add details on Backward edge limitations
That's all about second generation mitigations. We will look at error detection tools in next section.






