
Data Storage virtualization in Linux (Part 1)
Learn how to use file storage in Staas services. In file storage we create a file and use it as our virtual partition then format it in desire file system and mount it. All the operation we do in our real disk partition(/dev/sda*) can be done on that with some little tricks or manipulation.

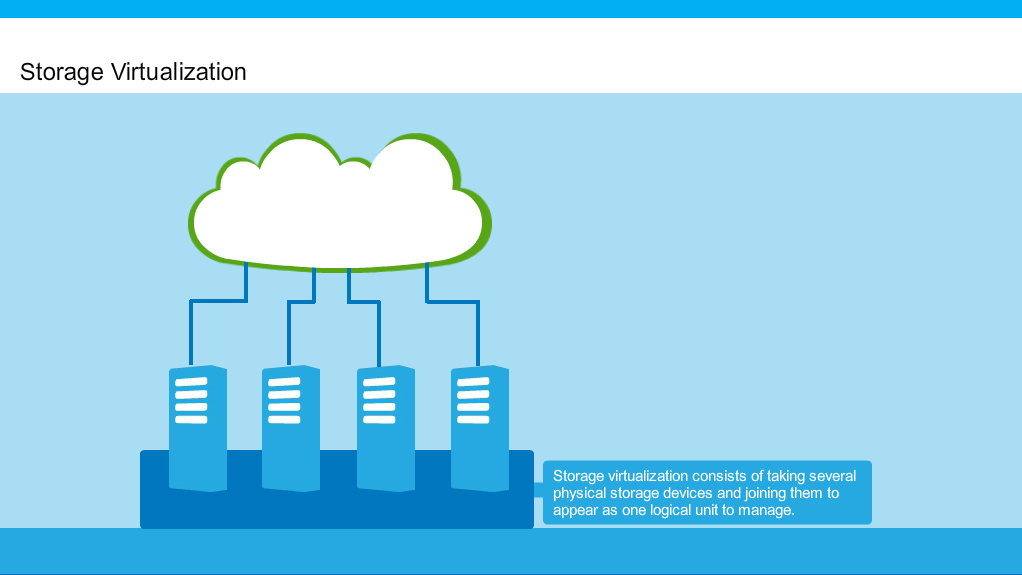
We can't deny the fact that traditional model of data management and hosting has been changed and user want their data/resources to be centralized and much flexible. By the innovation of virtualization technology it is become much more easier for large organization and even small businesses to centralized not only their storage but also every other thing they came across in IT world. But due to rapid increase in structured and non-structured data, a nice management for storage is required and resources have not to be wasted.
If we talk about storage as a service(Staas) in cloud computing, if you are a cloud service provider then lots of your resources get wasted since once you allocate a fix storage space to any client, its lots of part get useless since he never use them at once and you are not allowed to allocate them to others. To solve or minimize problem like that, it will be a good initiative to use file data storage as shared storage solution rather then object storage or storage attached network (SAN).
In this article I will try to get you through step by step procedure of using and managing file storage solution and also uses of qemu-img virtualization. I will even try to get you through some new techniques/operations of disk virtualization which can be really useful at some point to your cloud server.
I have used all simple techniques which can be easily understandable and are not so eye catching but will really help you at different level of storage system development and management.
All tools used are generally available on most on the linux system, if not then can be easily downloadable via your default online repository. The tested system for these commands is *RHEL 7.0* but they will work on other linux system in same way or with little steps rearrangements.
What is file storage?
If you are a Staas provider you will one day definitely come across a problem that lots of your storage actually get wasted since if a user purchases 10GB of storage space from you,then you are forced to allocate him his 10GB regardless of the fact that he not gonna use all of his space at once. Another frequent problem can be if your data storage have 100 GB storage left and you are thinking to buy new storage disk in few days. If in the mean time if someone unexpectedly demands you 200 GB storage then you have to refuse him to provide that. But a good provider is which who fulfill all users requests and provide 24/7 service. So a better solution for that is to use file storage. Through file storage you can scale your storage according to data inside it and even allocate that much of space which you even don't have.
File Storage are rely on the fact that everything in your operating system is a file. In file storage we create a file and use it as our virtual partition then format it in desire file system and mount it. All the operation we do in our real disk partition(/dev/sda) can be done on that with some little tricks or manipulation. For this procedure we use sparse images as our disks file.
So, what are sparse file?
A sparse file is a specific type of file which aims to use file system space more efficiently by using metadata to represent empty blocks. In the case of a sparse file, blocks are allocated and written dynamically as the actual data is written, rather than at the time the file is created. So the point is if you create a 10Gb sparse file it will not even take 1Mb of your disk space but its property info will show 10GB as it is the allocated space.So lets start the procedure we need to follow with spase file.
A sparse file can be created by either using truncate or dd utility in linux (another tools are also available).
$truncate --size=1GB test.img
This will create a 1Gb sparse image test.img. To get same result with dd use
$dd if=/dev/zero of=test.img bs=1024 count=0 seek=$[1024*1000]
here bs is block size and size is provided by seek, you can also use this for simplicity
$dd if=/dev/zero of=test.img bs=1 count=0 seek=1G
if you want to allocate the whole disk space at once(which is not a good solution in our case) then you can use fallocate for that
$fallocate -l 1G test.img
A little fun trick:
Can I create a 2TB partition on my 1Tb hard disk?
the ans is yes!.Since sparse file have property to not take the space while creation hence you can use them to do that$truncate –size=2TB mylargefile.imgcreate any desired file system on it
$mkfs.ext2 mylargefile.img $mount mylargefile.img /mnt/now you have a 2Tb partition which you can show to your techie friend to impress. :p
After creating the file you can format it and directly mount it to use as your storage but to make it possible to do lots of disk operations, it first have to connect to loop device using losetup utility. To attach the file to your loop device use
$losetup -f test.img
were test.img is your formated file. To see all such file or block device connected to loop device use
$losetup -a
you can easily grep the last created loop device by
$losetup -a | tail -1
After creating the loop device its time to format it. You can use any file system but my recommendation is using ext2 file system(the reason will be explained later).
To formate use mkfs utils
$mkfs.ext2 /dev/loop0
If you are working on big data management then xfs filesystem have to be preferred because it works well on handling large file and support larger inode data.
Now you can mount your formatted loop device to use as your virtual storage to share
$mount /dev/loop0 /mnt/
To share it across network using service like nfs,open /etc/exports add this entry
$cat /etc/exports
/mnt/ *(rw,rsync,no_root_squash)
close it and restart the nfs service by
$service nfsd restart
once you put the data inside the device you can check its original occupied size by using qemu-img utility
$qemu-img info test.img
or by du command
$du -h test.img
Since our file storage is ready, in next part we will look into common disk operations you can do with file storage.Stay tuned!



